Planning with Diffusion for Flexible Behavior Synthesis
TL;DR:
"The core contribution of this work is a denoising diffusion model designed for trajectory data and an associated probabilistic framework for behavior synthesis."
Available:
Planning in Reinforcement Learning
Planning in Reinforcement Learning is another way of saying trajectory generation; what sequence of generated steps can an agent take with respect to the environment model while maximizing the accumulated reward.
With respect to Offline Reinforcement Learning, planning requires a learned model of the environmental dynamics. Issue arises when the learned model is not well attuned to the task at hand. Very poor inter-task ability is displayed as policies are tuned to specific executions of tasks that do not generalize well to new environments.
Further loss is incurred due to a series of factors as discussed in the primer for Diffusion Models for Reinforcement Learning Survey.
Planning with Diffusion
- "The denoising procedure can be seen as parameterizing the gradients of the data distribution;"
- Much finer control over planning
- By blurring the line between model and planner, the training procedure that improves the model’s predictions also has the effect of improving its planning capabilities.
Architecture:
- an entire trajectory should be predicted non-autoregressively
- each step of the denoising process should be temporally local
- the trajectory representation should allow for equivariance along one dimension (the planning horizon) but not the other (the state and action features).
Learned long-horizon planning
Planning with diffusion removes single step updates of the trajectories and instead relies on "hindsight experience replay."
- Future goal states are included within a given step; As such the training process is not Markovian, future actions impact the past over several iterations of denoising the planned trajectories.
Greatest strength is this is especially viable in "sparse reward space" environments wherein the typical shooting-based trajectory optimization and planning methods lose performance in.
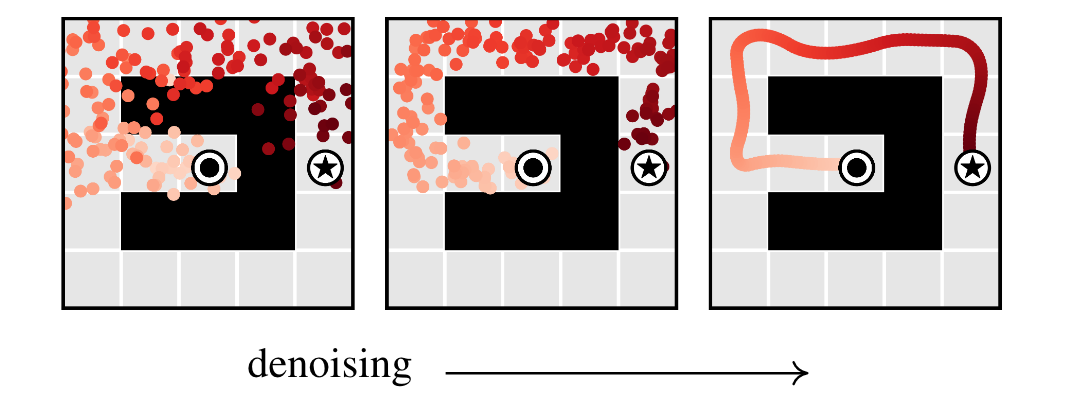
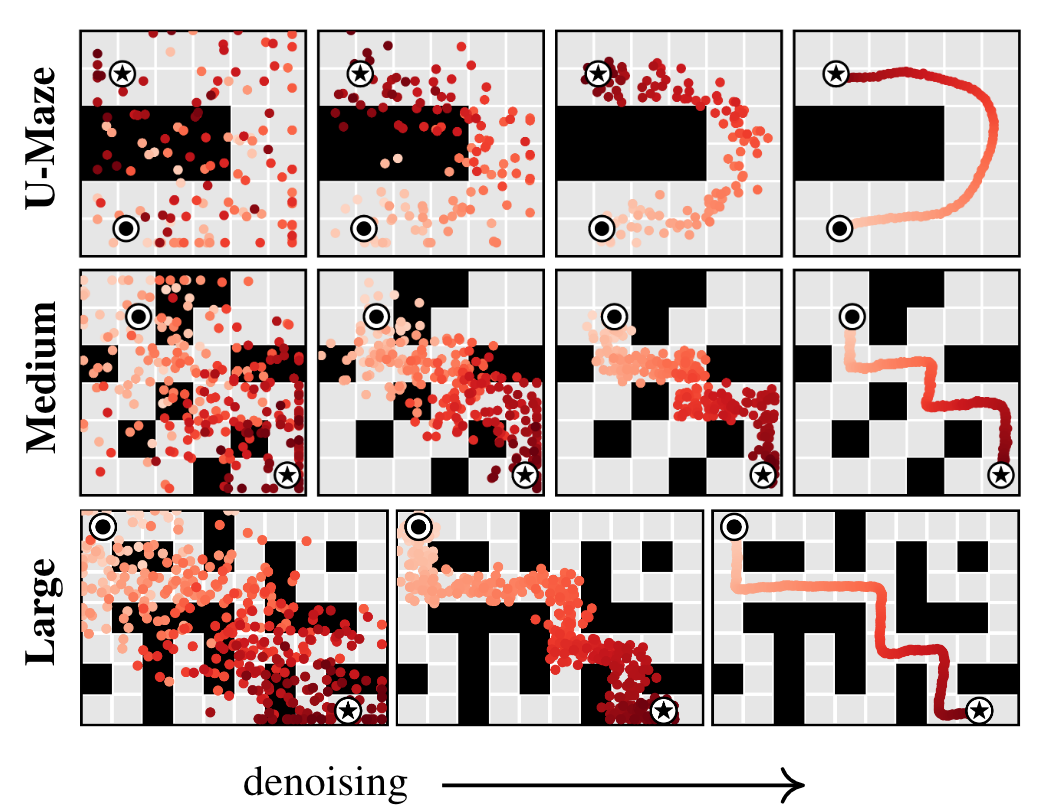
Temporal compositionally (basically locality)
Trajectories are optimized across every step all at once, and a nice property that arises is the maintenance of local fidelity in the paths generated from the denoising procedure.
- This results in locally viable structures propagating throughout the trajectory increasing accuracy. This results in performing trajectories that are not within the training data through composing different paths.
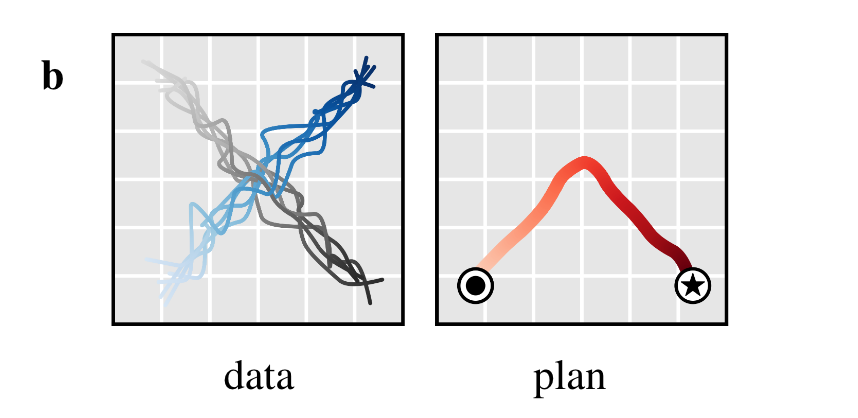
Task compositionality
Further, beyond doing well in sparse reward environments, diffuser is independent of the reward function as it acts as a prior over feasible paths.
- Changing tasks is equivalent to adding perturbation h(t) functions to the denoising step


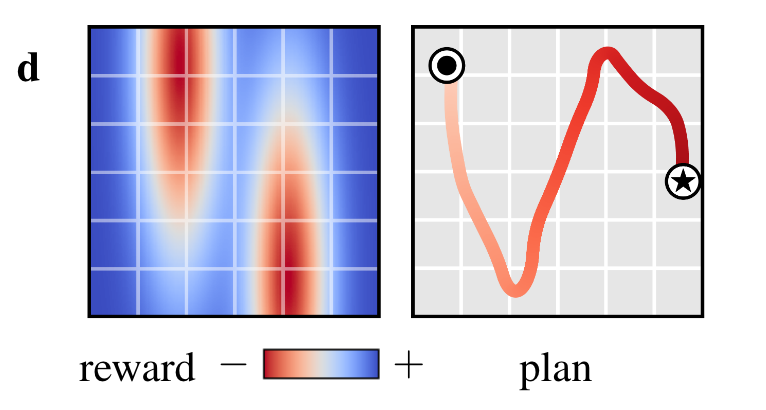
Experiment: Planning as Inpainting
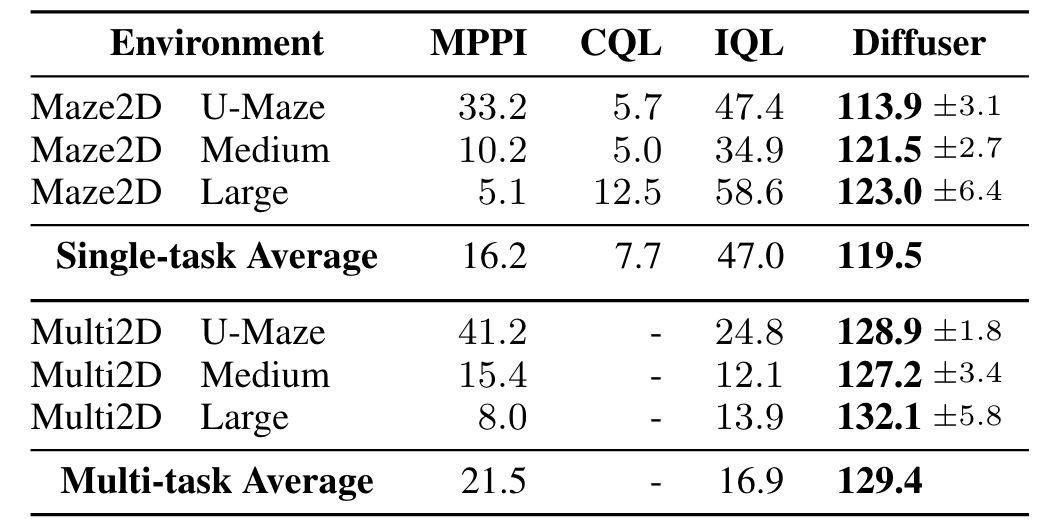
- multi-task is resampling a new goal at the beginning of every episode
How do we improve? AdaptDiffuser